haveged - A simple entropy daemon
/dev/random
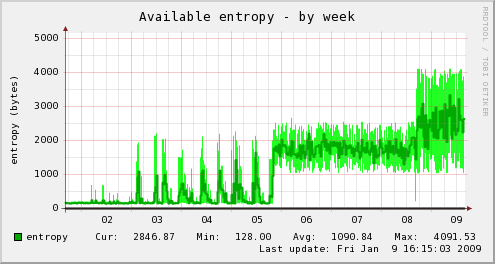
The Linux random number generator is the part of the kernel that attempts to generate randomness from operating system events. The output of this generator is used for TLS/SSL protocols, TCP sequence numbers, as well as other more conventional cryptographic uses.
For a (technical) discussion of the random number generator in the 2.6 kernel, see http://eprint.iacr.org/2006/086. For our purposes here, we need only to understand that all randomness is ultimately traceable to a hardware interrupt. Since by definition, hardware events do not arrive on demand, any randomness extracted from these events must be pooled for use when needed.
Linux uses multiple pools to manage random information and uses "entropy"
(apologies to Shannon) to quantify the number of bits currently available in those
pools. Device file interfaces to these pools come in blocking (/dev/random) and
non-blocking (/dev/urandom) flavors with state available in the
/proc/sys/kernel/random interface.
Entropy Shortages
Entropy is collected in Linux from a quantity constructed from the time of day and interrupt specific information. Unfortunately, only a small part of this information is usable for feeding the random pool and these sources are heavily weighted toward user interaction (the relative number of unknown bits per event is roughly 8/keyboard, 12/mouse, 3/disk, 4/interrupt). On a headless box without keyboard or mouse, entropy can become scarce - see the left of the graphs above.
Other Solutions
Some lucky folks have RNG hardware and for those folks, Linux provides rndg to feed entropy into the random pools. If you are not that lucky but want to throw hardware at the problem, google should bring up plans for building your own from the guts of a smoke detector, or you can use audio-entropyd or the like to make use of the Johnson noise of a sound card.
I have problems with all of these approaches.
- I quibble with the efficiency of rngd since it is basically timer driven.
- Hardware breaks sooner or later and rngd has no sanity check on its input. If you are using rngd, you need some sort of monitor or risk a silent failure.
- You may not have easy physical access to the box.
There is another solution often offered on the net - using urandom as the input to rngd. I did try this from 01/02 to 01/08 as shown in the graph above. It took a tight 1 second poll to build up any consistent entropy level.
Ultimately, I decided that urandom was a bad idea. To see why, look at figure 2.1 in Gutterman, Pinkas, and Reinman (page 5). You will see that pulling from an empty urandom pool, triggers a fill from the primary entropy pool - the thing you are trying to fill! I don't know of anyone who has really tested what the result of this is, but the output of any pseudo random number generator has to have a hardware seed somewhere and this arrangement looks prone to generating artifacts. And since there is no check on data sanity in this arrangement so who knows what is really in the random pools?
Another solution offered is to schedule periodic disk intensive tasks just for the purpose of feeding the pool. Because the entropy per disk event is so low, this would require a lot of churn to make any difference. Next!
HAVEGE
Anyone who has ever had to benchmark software will understand the idea behind HAVEGE. The timing for the execution of a fixed piece of code is unrepeatable even in an idle machine. Hidden processor features such as instruction and data cache, and the associated virtual memory translation tables are constantly in flux from the action of interrupt service routines and effects of this are observable in userland. HAVEGE uses differences in the processor time stamp counter during the execution of a completely deterministic loop to collect these variations. The loop is designed to exercise both the instruction and data caches. An early (technical) description of the design of the algorithm can be found here.
My idea was to use the HAVEGE algorithm to fill the random pool using something like the rngd approach. The original proof of concept was called haveged and used the static library version of the library from the HAVEGE authors. The method for building this library made heavy use of the preprocessor to construct an algorithm tailored to an environment. Problems with this approach included the use of magic numbers to unroll the collection loop based on compilation options that did not work in my environment (the required optimization caused segfaults).
The Design of haveged
The HAVEGE library supported x86, ia64, ppc, and sparc environments using the gcc compiler. Hardware specific code used in-line assembly defined as macros within the "havegedef.h" include. The build system selected the macro source for each definition on the basis of the host targeted by the build system. The macro to read the processor time stamp counter was then used to construct the basic build block of the entropy harvester in the "oneiteration.h" include.
In practice, the collection sequence consisted of a branch-heavy calculation that read the processor time stamp readings into an data array as it permuted the array contents. The data array was sized to be twice that of the level 1 data cache and the calculation constructed so that 2 cache blocks were party to each output calculation. The calculation would be cyclical if not for the effects of other unrelated hardware events on the time stamp counter increments.
The compiler used to build the collection algorithm has a large impact on the operation of the algorithm because for best results in detecting variations related to execution related processor features, the collection sequence should nearly fill the processors level 1 instruction cache. The compiler also directly impacts the detection of data related state changes because aggressive optimization could eliminate or rearrange memory access so as to defeat the design of the collection algorithm. In the real world, the second concern has proven more difficult than the first.
Compiler issues are difficult to deal with correctly. GNU auto-tools provides the most portable build environment but places compiler optimization options in the hands of the user and in the case of gcc, provides a fairly aggressive optimization default (O2). Worse yet, the build settings always target specific settings which would override any attempt to specialize options for a particular compilation. Therefore, any attempts to prevent overly-aggressive optimization should rely on structural mechanisms within the code itself.
Furthermore, using auto-tools to size the collection loop made HAVEGE difficult to deploy. Instead, the haveged design uses a fixed-size collection loop and uses a run-time calculation to limit execution over only the portion of the collection loop needed to fill the instruction cache. A variation of "Duff's Device" is used create a collection sequence formed by 40 labeled repetitions of the original "oneiteration.h" macro and the humble "goto" is used to route execution within the bounds of the instruction cache size.
The processor information in /proc/cpuinfo does not provide the level of information required to configure the haveged collector. However, most x86-style processors provide a cpuid instruction which can be used to get the required information. If the instruction is available, haveged will attempt to determine the required cache size settings if available. If the cpuid determination fails or the cpuid instruction is not present, a "generic" default of 16KB will be used for both cache sizes and a "generic tuning" diagnostic issued at start up. Cache sizes can also be specified on the command line to override the default for either or both sizes and are the final fallback when all other configuration attempts fail.
Because HAVEGE operates from user land, the design of the actual daemon is very simple. The daemon collects entropy harvests in a 8MB buffer which is read byte by byte and refilled as necessary. The daemon suspends itself on the random device waiting for a write_low_watemark event. When the event is read, bytes are taken from the harvest buffer and written to the random device until the pool is filled.
The Implementation of haveged
The haveged daemon was developed on CentOS using a 2.6 kernel but should run "as is" on " Enterprise Linux 5" systems (RHEL 5 / CentOS 5/ SL 5). The original HAVEGE support for non x86 architectures has been retained (PPC, SPARC, IA64) and some adjustments put in place for 2.4 kernels but all of these features remain untested. The package uses GNU auto-tools for the build platform. I don't have any information on coverage, but the binaries are known to build on gcc versions 4.2 through 4.5, on the CentOS, Debian, Gentoo, openSUSE, and Ubuntu distributions, in both x86 and x86_64 environments. The primary package consists of the daemon, a start up script (a CentOS version is supplied), and the man page. User supplied adaptations are included in the contrib portion of the package.
Two test programs are provided in the package to verify the operation of the HAVEGE random number generator. Because there are many complex factors that affect the operation of the HAVEGE algorithm, the operation of the random number generator should be verified before the daemon is installed. The make check target executes a simple test based upon the public domain ENT source, but for the truly paranoid the NIST suite adaptation from the HAVEGE authors is also provided.
Compiler Wars
The original collection sequence used a table of relative label displacements from a common dispatch point at the end of the unrolled loop (aka the 'code size'!!) to size the collection loop. The first call to the collection routine would scan the table to determine the correct index for a computed goto transfer to the proper start point of the in-line collection sequence. This scheme was used until very recently but repeatedly succumbed to ever-improving compiler optimizations that rearranged and modified the expected code in unexpected ways which was usually announced with a seg fault.
Applying 'volatile' declarations tamed some of these problems but a better approach was needed. I was also interested in loosening the algorithms dependence on gcc specific features. This resulted in a first-principles rewrite of havege with the goal to make the algorithm portable to both the linux and windows build environments for further evaluation. As it turns out the windows "/Ox" build proved much to be less of a problem than the test suites which still misbehave. If I sort those, I might be tempted to create another package for those folks who need a good non-deterministic RNG in windows.
On the test suite front, I have been using the unmodified NIST statistical suite in recent testing in both environments. I had once thought of replacing the current NIST adaptation, but I am not so sure any longer since the suite is huge and the results are harder to interpret.